ハードウェアウォレットを買った:後編

前回のあらすじ:
暗号資産が盗まれて資産がすっからかんに遭っている方を目の当たりにし戦慄した私。
自分が無一文になってしまう強い不安に襲われた。
そこで「自分の資産は自分で守る」ために、ハードウェアウォレット(とオマケでシードフレーズを記録する金属プレート)を買ったのでした。
今回は、ハードウェアウォレット「Ledger」の使用感を述べようと思う。 本当はソラナコラボのLedgerが欲しかったけど待てなかったのでNano-Xにした。
「Ledger」初期セットアップ
外見
こんな感じで大きさも見た目もUSBメモリのようだ。
USB/Bluetoothを使ってPCやスマホと連携して使う。

まずは本体PIN設定
最初に PIN を設定。4~8個の数字をPINに設定できる。
最初はセキュリティを考えて8桁にしたが、すぐに8桁の入力が面倒になり4桁に変えた。
ちなみに3回PIN入力失敗するとLedgerが永久ロックされる。
ロックを解くためには初期化しかない。
シードフレーズ生成
次に24語のシードフレーズが順番に表示される。
このシードフレーズを元にして全ての暗号資産の秘密鍵を生成する。
つまりビットコイン含めた暗号資産の全ウォレットを復元する鍵になる。とんでもなく重要なフレーズだ(震え
ちなみにシードフレーズが表示されるのはこの時だけ。
間違いがないように何回も見直しながら書き写した。
そして、絶対に絶対に、このシードフレーズをメモ帳で保存などはしてはならない。
何かのきっかけでシードフレーズがPC上から流出した場合、ハードウェアウォレットである意味が無くなるためだ。完全にアナログで管理する必要がある。(そのための金属板だ)
Ledger Live の導入
Ledger Live をスマホにインストールしてLedger本体と通信設定をする。
Bluetoothを使うのだが、ペアリングで苦戦した。スマホとLedgerの双方のデバイスで許可すべきところを、スマホだけで許可して待っていたため、タイムアウトでペアリング失敗を繰り返した。
Ledgerでも許可するってわかればスムーズに設定完了すると思う。
ファームウェアの最新化
「Ledger Live」を使いファームウェアを最新にした。
1回で最新Verにはならず、3回ぐらい順番に適用が必要だったため時間がかかった。
ちなみに、1回目のファームウェア適用完了後?にスマホ側が待機状態から完了状態に遷移せず混乱した。
あまりの待機時間に待ちきれずにアプリ終了して先に進めてしまったが、きっとNG行為だろうな。2回目3回目で正常にアップデート適用できたので問題なかったと思いたい…。
ソラナアプリ導入
ファームウェア最新化完了後にやっと利用可能な状態となる。
ただし、このままでは何の暗号資産も扱えない。
ではどうするか?
通貨ごとにアカウントを追加(アプリをインストール)しなければならない。
自分は取り急ぎソラナアプリをインストールした。
有名どころの通貨は殆ど網羅している感じだった。
日本の取引所で扱っているような通貨であればまず心配はないだろう。
ソラナウォレット作成
実際にソラナで使うウォレットを作る。
自分も初めて知った(意識した)のだけど、BIP44というルールに測って、一番最初に生成したシードフレーズからウォレットを生成する。
ちなみに同じシードフレーズからウォレットは殆ど無尽蔵に近い数が生成できる(暗号資産の世界っていちいち壮大だ)
なお、BIP44の説明はまたの機会か、別の人に委ねます(:3 」∠ )
ちなみに自分は Solflare にLedgerを接続してウォレットを作成した。
使用前の最終確認
ここまでで暗号資産を扱う準備は万端だ。(自分の場合はソラナ)
ただ、いきなり大きな額を扱って資産が動かせなくなるリスクは避けたいので、以下2点を試した。
少額資産(0.1SOL)で資産の受取/送信確認した
HWWに資産を入れても、他に移動できないと元も子もない。
少額でのトークン送受信の確認は必須だと思う。
シードフレーズからウォレットを復元できるか確認した
これも心配性だから試した感じ。
下準備として、LedgerのPINロック解除をわざと3回失敗して永久ロックさせる。
そこから再度初期設定→書き留めたシードフレーズからウォレットがリストアできるか確認した。
結果、問題無し。ε-(´∀`*)ホッ
ハードウェアウォレットの使い心地
HWWが必要になるシーンは「取引承認時」
資産取引発生のたびにLedgerを用いて「承認」が必要になる。
ウォレットの残高確認のみであれば、Ledgerは不要だ。
覚悟はしていたがソフトウェアウォレットよりも断然手間がかかる。
ただ、この面倒な方式であれば、PCやスマホのウォレットがハッキングされても(ある程度は)安心だ。
取引の署名に使う秘密鍵はHWW内にしか存在しないためだ
ソフトウェアウォレットと比較するとハッキングによる秘密鍵漏洩の心配はほぼ皆無だろう。
注意点として、Ledgerを用いているからといってむやみに取引を承認してはならない。
身に覚えの無い取引は決して承認しないなど、細心の注意は引き続き必要だ。
取引承認は緊張する
Bluetooth接続のせいか取引実行してからLedgerに承認通知が来るまで2~3秒の待ち時間がある。
その時間が妙に緊張する。慣れでしょうか…。
なぜかChromeからは取引承認が出来なかった
自分の端末が悪いのか、PC版のSolflareとLedgerの組み合わせに問題があるのか不明だけど、取引承認→Tx成功って出ているのに結果がウォレットに反映されずにとても焦った。スマホ操作だとそんなことは起きなかったので当面スマホを使うことにする。
LedgerでBOT取引はむずかしい
Ledgerは毎回手動で物理ボタンを使って取引承認の必要があるので、BOT運用は難しいだろう。
BOTで緊急時のトークン避難場所として使うなどは良さそうだ。
逆にLedgerを前面に出してBOT運用している人が居たら凄いと思う。
現状の課題
ソラナ以外のトークンも管理するか?
ソラナはDiFi取引が多いのと詐欺報告が多いので真っ先にHWWを導入した。
他の資産(特にビットコイン)はどうしようか…悩んでいる。
現状、国内の取引所に保管しているだけで何もしていない。
これから考えたい。
保管場所はどうするか?
Ledgerの保管場所って結構悩む。
Ledger自体は取引するときに必要になるので使用頻度がそこそこ高い。
今の所、スマホの近くに置いてある。せいぜい引き出しに入れておく程度かな…
移動時は持ち歩くか?
外出時もソラナを触りたい!
その場合は、Ledgerも持ち歩かないといけない。
だがしかし紛失リスクも怖い。
長期間、家を空ける時以外は、むやみにやたらには持ち歩かない方が良いだろう…。
壊れたらどうする?
壊れた時に考えることにした笑
一応、復元パターンだけは検討した。
新しいLedgerを買って復元
- メリット
-
引き続き同じアドレスをハードウェアウォレットとして使用可能。
これに尽きる。 - デメリット
-
注文してから届くまで1~2週間ぐらい時間がかかる。
その間に自分の資産にアクセスできなくなる。
大きな価格変動があった場合は心配。
シードフレーズからソフトウェアウォレットで復元
- メリット
-
壊れても直ぐに自分の資産へアクセスができる。
- デメリット
-
ハードウェアウォレットとしては使用不可になる。
※秘密鍵がインターネットに繋がった環境に存在してしまうことになるため。
さて、どうするか?
理想の手段
故障時に備えて予備のLedgerをストックしておく(金持ちしか無理だ)
現実の手段
壊れた時に考える ←残念だけど、これにした
あとソフトウェアウォレットで復元できる手段だけ予め確認しておく。
今時点のまとめ
ハードウェアウォレットは資産管理のゴールではなく、むしろ新たな旅の始まりだった。
考えることが山積みだ。
秘密鍵の漏洩リスクは除去できたが他にも様々なリスクが存在するため、これで安心っていう心理状態にはならなかった。
あとLedgerはソフトウェアウォレットの操作に少し慣れてきた人じゃないと厳しいかもしれないと感じた。
追記: シードフレーズを管理する金属プレートに対する感想は気が向いたら書きたい。
ハードウェアウォレットを買った
暗号資産を触ってると、とんでもない事件が日常的に起きる。
- 天変地異的な価格変動
- 取引所のハッキング
- 盗難/詐欺
自分のマイブームは言うと、Solana上でのDeFi取引だ。 その際、Solanaを自分で作成したウォレットに移動することになるが、このウォレットがクセモノだ。
自分の身の回りに「ウォレットから資産が抜かれた!」という報告が相次いでいるためだ。 その被害額も数十万円の世界ではなく、数千万円以上が一瞬にして無くなるという感じだ。 自分はそんな大金を動かしていないけど、とても他人事には思えない。
自分が同様の被害に遭った場合、資産が戻ってくることはなく、助けてくれる人も居ないだろう。 自分の身は自分で守らないといけない。
いますぐやる対策
- ハードウェアウォレットを使う
- シードフレーズはデジタルデバイス上に保管しない
まずはハードウェアウォレットを買った
…でタイトルのとおり、ハードウェアウォレットを買った。
ウォレットには幾つか種類があるが、今自分が使っているのはソフトウェアウォレットでハッキング被害に遭いやすいとても脆弱な存在だ。
それと対比される存在がハードウェアウォレットだ。 存在はかなり前から知っていたが、自分とは無縁のものと思っていた。 もっと大金を扱う人が使うものと考えていたが、これだけ被害報告が多いと自分で出来る対策は早めに打っておいた方が良いだろうという判断だ。 あと数万円で手に入るというのも良い。決して安い買物ではないけれど、被害に遭うことと比べたら全然マシ!と思った。
ハードウェアウォレットは、あまり考えずに有名どころの Ledger にした。
Ledger(https://www.ledger.com/ja)
シードフレーズの管理
対策②は、対策①で新たに導入するウォレットのシードフレーズは金属プレートで管理する。
金属プレートは手ごろな imkey社の製品を導入する。
imKey HeirBOX(https://imkey.im/products/imkey-heirbox-s1)
シードフレーズは絶対にPC上では保管せず、オフライン保管を心掛ける。
クラウドに保存なんてタブー中のタブーだ。
(自分がそうだった OTL)
どちらも実際に運用を開始したらまた報告したい。
NandGame攻略メモ(Hardware編)
- Introduction / はじめに
- How to Play / 遊び方
- Further Reading / 参考資料
Introduction / はじめに
NandGame は簡単なコンピュータを作るブラウザゲームです。 コンピュータ内部の仕組みを理解したい方におすすめです。 様々なサイトで攻略情報が公開されていますが、自分用に情報を纏めたかったので記事にしました。
さて本ゲームの趣旨ですが、Nandゲートを出発点とし徐々に複雑な演算回路を作り上げてゆきます。
そもそも、なぜNandが出発点なのでしょう。 それは、Nandのみを組み合わせれば、全ての論理ゲートを作れるからです。 もうこの時点で強烈なロマンを感じませんか?
NandGameの興味深いところは、最初の一歩としてNand自体もリレースイッチから作るところです。 これは他の類似コンテンツには見られなかったアプローチです。 確かに視覚的に挙動がイメージできるどこにでもあるスイッチからNandがつくれるというのは、コンピュータアーキテクチャの深淵へ挑む偉大な一歩です。
各課題は、最も少ないNandゲート数でクリアすると「This is optimal!」と褒められます。 最適化できていなくても次の課題には進めるので、最後のやり込み要素として突き詰めるのも楽しいです。
NandGameは情報数理/論理演算の知識があるとより理解が深まります。 知識がなくても、試行錯誤で解ける問題も多いので、まずは手を動かしてみるのが良いでしょう。
楽しみ方は人それぞれですので、自分のペースで進めてみてください。
How to Play / 遊び方
NandGameは以下のような画面で始まります。

左に課題が表示され、右にコンポーネントとキャンパスがあります。 課題に示されている入出力仕様を満たすようにコンポートネントを配置&配線し「Check solution」を押してテストをクリアできれば次に進めます。
前半はパズル要素で解けると思いますが、中盤からは論理演算や数値表現に関する基礎知識がないとゲームを進めるのが難しくなります。 下記に参考となる書籍を紹介しますので、興味があれば手に取ってください。(ちなみに2冊とも名著of名著です。)
Further Reading / 参考資料
下記書籍がNandGameでは説明できていない部分を理解するのに役立ちます。
Hardware Tips / ハードウェア攻略メモ
ハードウェア編はNandゲートから始まり、最後はプログラム内蔵方式のコンピュータ構築となります。 定期的にステージ構成が変更となるので注意です。本記事は執筆時点(2024年8月)の構成です。
Logic Gates / 基本論理ゲート
Nand
リレースイッチからNandゲートを作成します。 最初、Nand自体の作り方を知らなかったので躓きました。
Hardware編ではこのステージのみ Power(+)端子(電源)が登場しますが、次のステージから電源は暗黙の了解として隠蔽されます。
作り方は、電源ON時スイッチONと電源ON時スイッチOFFのリレーを1つずつ使いNandが構築します。
実際のNand構築はMOSFETを使いますが、Nandgameでは最初にリレーを使います。確かに視覚的に分かりやすくて良いですね。最近知ったのですが、ハードウェア、ソフトウェアを全てクリアすると「Optional Levels」が出現し、MOSFETを使ったNand作成ステージもあるようです。qtumはそこまで進めていません。

Invert (Not)
Nandゲートを使ってNotゲートを作成します。 本ゲームではInvertと呼ばれます。Invertは「反転」という意味があります。
Invert(NOTゲート)の構成は至ってシンプルです。 Nandゲートの両入力に同一の信号を与えることで、Invertを実現できます。
NANDゲートの真理値表を確認すると、入力AおよびBが同じ値を取るとき、出力がその値の論理反転となる特性があることがわかります。 この性質を巧みに利用することで、効率的かつ簡潔にInvert機能を構築することが可能です。

And
Andゲートは、Nandゲートの出力をInvert(Notゲート)で反転させることで実現されます。 多くの方は論理演算を初めて学んだとき、Andゲートを最初に学んだのではないでしょうか? その後にNandゲートやNorゲートが登場します。 しかし実際の論理回路設計ではNandゲートを最小単位と見做すことが多いようです。

Or
ド・モルガンの法則を覚えていますか? 私は忘れてました。
Orゲートはド・モルガンの下記法則を活用して、InvertとAndを組み合わせて作成します。
このままだとOrではなくNorになってしまうので、左辺をOrにするため2重否定にします。
2重否定は打ち消せますので、下記のようになり Orゲートを導く論理式が得られました。
あとは得られた式の通りに、InvertとNandを配置してOrゲートを作成します。

Xor / 排他的論理和
基礎論理ゲートの最後で、Xorゲートを作成します。 暗号理論では大活躍する論理演算の1つで様々なシーンで登場します。
覚えていれば簡単ですが、無の状態だとパッとは思いつきません。 こんな時はカルノー図を作成してみましょう。
上記より、Xorゲートは下記のように表現できます。
今回も導いた式の通りにコンポートネントを配置してXorゲートを作成します。

Arithmetics / 算術回路
Harf Adder / 半加算
算術のスタート地点は足し算をする半加算器です。 半加算器は、2つの入力AとBを受け取り、和とキャリー(桁上げ)を生成する基本的な回路です。 非常にシンプルな足し算しかできない回路ですが、この半加算器を理解することが、全加算器やALU(算術論理演算装置)を理解する上での基礎となります。
「半」という名前が付いているのは、下位の桁からのキャリー(桁上げ)を考慮していないためです。 次に出てくる全加算器作成の前段階と考えれば良いでしょう。
半加算器では下記4通りの足し算ができます。ホントに単純な回路ですね。
半加算器の真理値表は、上記の演算結果をそのまま表しており、内容は下記の通りです。
"h" と "l" をそれぞれ見ると、"h" は入力AとBのAnd、"l" は入力AとBのXor となっていることが分かります。 これに気が付けば半加算器はもう完成したも同然で、回路は下記の通りとなります。

Full Adder / 全加算
全加算器は、半加算器に対して下位の桁の桁上げを考慮した回路です。
全加算器で実現したいことは、下記の3つの足し算です。 我々が筆算で2桁以上の数字を足すときに2桁目以上は桁上げを考慮して計算しているのと同じです。
全加算器作成のポイントです。
- a+b の結果に c を足す。(つまり半加算器を2回使う)
- "h" の出力は、半加算のいずれかで桁上げが発生したかどうかを判定すれば良い。
上記を加味すると、全加算器は下記のようになります。

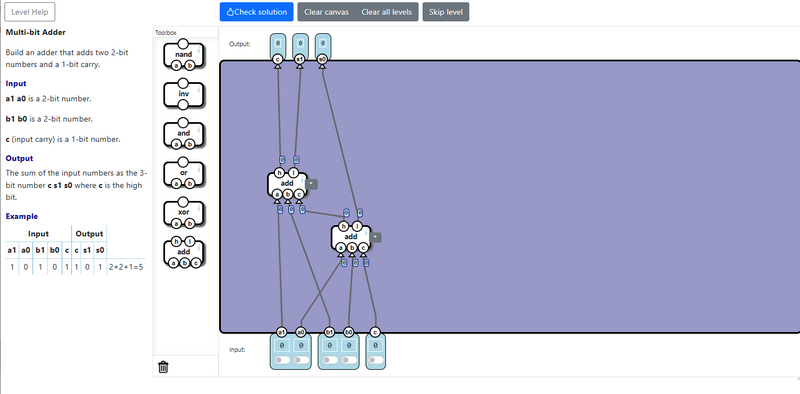
Multi-bit Adder / 多ビット加算機
全加算器が完成しても実現できる加算は所詮 1bit の 1+1+1 までです。 「2桁以上の加算はどうすれば!?」という要望に応えるべく登場するのが、多ビット加算機です。
組み上げる回路イメージを筆算風に表現するとこんな感じです。(例:2+3=5)
実際にどのような回路になるかというと、下記のようになります。 ポイントは、1桁目、2桁目… n桁目 と繰り上がりを次の桁に繋げば、いくらでもビットを増やすことができる点です。 今回のお題では2ビットなので、全加算器を2つ使った回路となります。
ちなみに、この課題以降は、16bitに対応した多ビット加算機がコンポーネントとして使えるようになります。
Increment / インクリメント
インクリメントは、加算器を使って入力値に1を足した値を出力する回路です。
今回使用するのは「add 16」で、16bitの全加算器です。 前回「Multi-bit Adder」を作成した流れからの登場です。
作成方法は、入力値に1を足すということなので、加算器の入力値として X と 1 を与えれば良いです。
― 入力値「1」はどう作るか? ―
応えは簡単で、コンポーネントで用意されている「0」をinvertで反転させれば「1」が得られます。 以上から回路は下記になります。

Subtraction / 引き算
今回の課題は引き算です。 加算器しかない状態でどのように引き算を実現するのでしょう?
鍵となる考えは「2の補数」です。
コンピュータの世界では、引き算は2の補数による加算で実現します。 2の補数に関しての詳細な説明はここでは割愛させていただきますが、ポイントがあります。 (2の補数の詳細はwikipediaを参照)
コンピュータの世界で整数を表現するには、2の補数表現が都合が良い → 限られたbitを無駄なく使えるのが嬉しい
負数は2の補数として表現する → 引き算が足し算で実現できるのが嬉しい
引き算が足し算になるということにピンとこない場合は、私たちが日常で使っている10進数で考えてみましょう。
例えば、 という引き算を、
という足し算で計算するようなものです。
3 を引いているわけでなく、-3を足していると考えるんですね。
-3 の2の補数の求め方は、+3を全ビット反転させ、+1 で求まります。 どうやら、今まで作った invertとincrementで実現できますね。
上記を加味すると、引き算は下記のようになります。

Equal to Zero / ゼロ判定
Equal to Zeroは、入力値がゼロかどうかを判定する回路です。
入力値をそれぞれ反転してAnd演算することで、入力値が全て0の場合のみ出力が1となる回路ができます。

Less than Zero / マイナス判定
Less than Zeroは、入力値がマイナスかどうかを判定する回路です。 マイナス判定は、負数が2の補数でどのように表現されるか理解しておけば簡単です。
結論から先に話すと、負数は最上位ビットが必ず 1 となります。
例として、3bitで表現できる整数(符号あり)を考えてみましょう。
そうすると下記範囲 が表現でき、最上位ビットが 1 の場合は負数となっているのが分かります。
NandGameでは、最上位ビットを取り出して判定するために、Splitterというコンポーネントを使います。 Splitterは、入力値をビットごとに分割するNandGame固有のコンポーネントです。
負数は最上位ビットが 1 というルールをそのまま回路に落とし込むと、下記のようになります。 特段、難しい判定ロジックは無く最上位ビットをそのまま出力すれば負数判定ができます。
非常にシンプルな仕組みです。

Switching / スイッチング回路
本セクションで作るのは、スイッチング回路です。 スイッチングを活用すると今まで作成した単純な論理回路から驚くほど高度な演算回路を実現する足がかりとなります。
スイッチングには2種類あり、1つは「セレクタ/(マルチプレクサ)」、もう1つは「スイッチ/デマルチプレクサ」です。 それぞれどのような回路なのか、どのように使うのか、どのように作成するのかをそれぞれ見ていきましょう。
Selector / セレクタ
セレクタは、複数の入力から1つを選択して出力する回路です。 日常の例だと、CPU切り替え器やAVセレクターなどがあります。 同じような働きを論理回路で実現するのがセレクタとなります。
ポイント
- n本の入力を切り替えるためには、log2(n)ビットの制御信号が必要になります。 例えば、2本の入力を切り替えるためには 1ビットの制御信号が必要で、4本の入力を切り替えるためには 2ビットの制御信号が必要です。
どのように実現すれば良いでしょうか?
答えは簡単で、入力信号と制御信号をAnd演算すれば実現できます。
その際、2つの入力信号のうち常に1つだけOnになるよう制御信号の片方をInvert(反転)しておきます。 これも加算器同様、1bitセレクタを作成すると、制御信号を1本ずつ追加することでnビットのセレクタに拡張できます。
回路は下記の通りです。

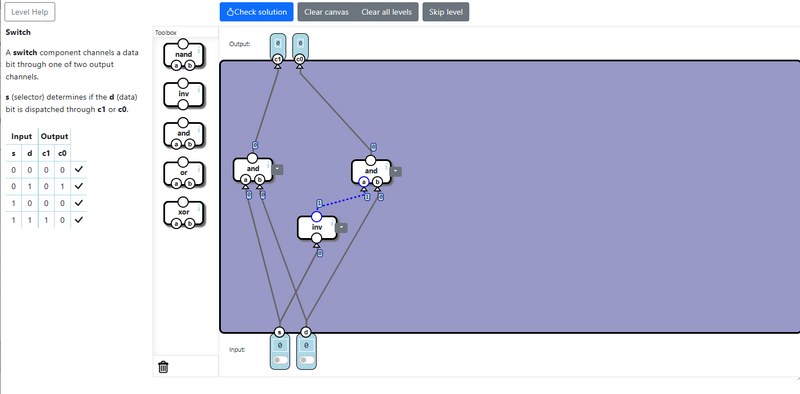
Switch / スイッチ
スイッチは、セレクタと逆の動作をする回路です。 1つを入力を複数の出力に分割します。
ポイント
- 1本の入力をn本の出力に分割するには、log2(n)ビットの制御信号が必要になります。 例えば、2本の出力に分割するためには 1ビットの制御信号が必要で、4本の出力に分割するためには 2ビットの制御信号が必要です。
実現方法ですが、セレクタと全く同じで制御信号とのAnd演算を使って実現します。 スイッチは出力を1本に纏める必要がないため、分割した信号をそのまま出力します。 回路は下記の通りです。
Arithmetic Logic Unit / 算術論理演算装置
いよいよALUの登場です。 以前のNandGameでは、ALUを1つのコンポーネントとして作成しましたが、改訂された現在のバージョンでは段階を踏んでALUを作成することで、構成がかなり分かりやすくなりました。
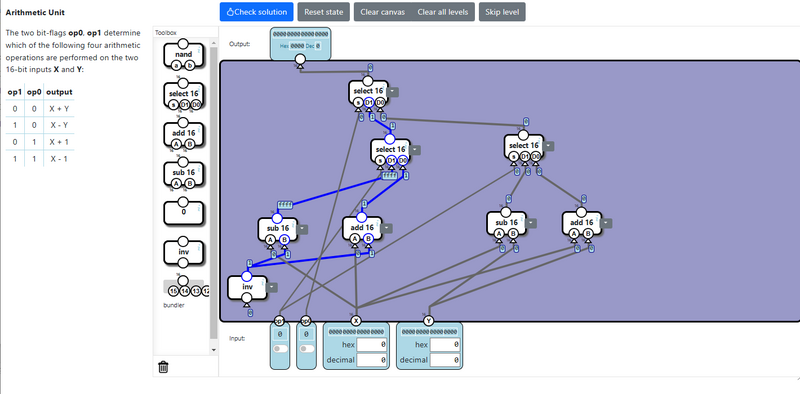
Arithmetic Unit / 算術演算装置
ALUの第1ステップは加減算を実行する回路です。 2bitの制御信号を使って、4つの演算(加算、減算、インクリメント、デクリメント)を実現します。 早速前段で作成したセレクタが早速活かされます。
演算ユニットを横に並べてツリー構造のような形でセレクタで出力を束ねていくイメージです。 この辺りは慣れるとあっという間に作れるのではないでしょうか。
Logic Unit / 論理演算装置
ALUの第2ステップは論理演算を実行する回路です。 2bitの制御信号を使って、4つの論理演算(And、Or、Xor、invert)を実現します。
「Arithmetic Unit」と同じ考えで作成できます。

ALU / 算術論理演算装置

Condition / 条件分岐

Memory / メモリ
SR Latch / SRラッチ

D Latch / Dラッチ

DFF / データフリップフロップ

Register / レジスタ

Counter / カウンタ

RAM / ランダムアクセスメモリ

Processor / プロセッサ、ノイマン型コンピュータ
Combined_Memory / 組み合わせメモリ

Instruction / 命令ユニット
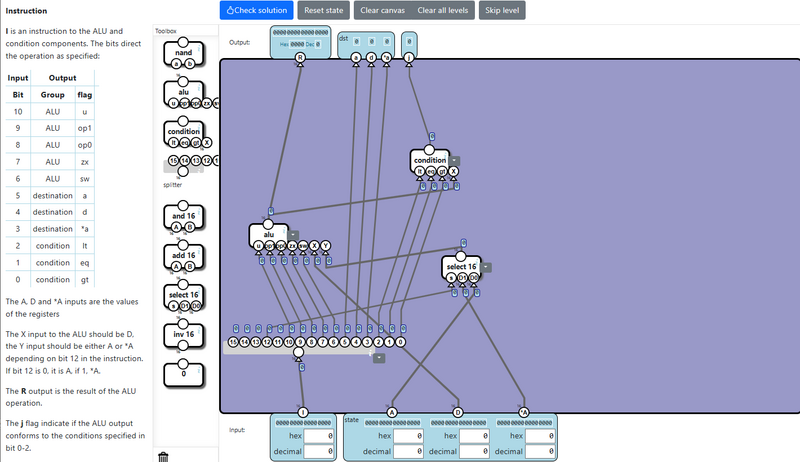
Control Unit / 制御ユニット

Computer / コンピュータ

Input and Output / 入力と出力

新NISA~辿り着いた答え~
インデックス最強!
結局、新NISAは以下のファンドを選んだ。 遠回りして色々物色してしまったが、もうこれ以外の選択肢が思いつかなかった。
- つみたて投資枠
- eMAXIS Slim 米国株式(S&P500)
- eMAXIS Slim 全世界株式(オール・カントリー)
- 成長枠
- eMAXIS Slim 米国株式(S&P500)
- eMAXIS Slim 全世界株式(オール・カントリー)
「どっちも同じファンド!?」と思われるかもしれないが、とにかくオルカンが最強に見えた。新興国や日本株TOPIXも考えたが、オルカンにしておけば地球上のすべての地域を賄えそうだ。
特定口座も継続中
自分自身ではなく、純粋な成長産業への興味と応援。 これは引き続き特定口座を利用する。
実は特定口座を使った積み立ては20年目になる。
おととし、マイホーム購入のためにある程度売却し、現在は新NISA移行中だが細々と続けている。
私が今回は選んだのは「たわらシリーズ」だ。
信託報酬が安く、自分が投資したかった分野が揃ってるためだ。
- たわらノーロード フォーカスAI
- たわらノーロード フォーカス次世代通信(5G~)
- たわらノーロード フィンテック
AI、5G、フィンテック。
それぞれの成長産業でインデックス型ファンドとなっていて面白そう。
どれも自分が過去に携わったり、ある程度は知っている分野なので、これからもっと盛り上がるだろうと思った。特定口座で始めたのは新NISAはS&P500とオールカントリーで枠を埋めて長期間放置の予定だからだ。
今後が楽しみだ。どんな波乱が待ち受けているか…。 追って報告したい!
新NISA
せっかくのブログだけど中々更新できないのが嫌だったので 長文に拘らず短文をさくっと書いていこうと思う。
最近、新NISAで投資する商品について考えている。
世間ではインデックス投資一択と言われている。 その中でも「S&P500」「オルカン」は特に人気が高い。
私もその投資信託を積立しているが、自分自身は投資自体が趣味というのもあり「何か面白いファンドは無いか」と日々色々探してしまう。
その中でも以下ファンドが気になっている。
- たわらノーロード シリーズ
- iFreeNEXT シリーズ
- eMAXIS Neo シリーズ
- SMT MiraIndex シリーズ
今年に入って自分は何のために投資をするのか?を自問自答し続けていた。
「儲けるため」以外に辿り着いたもう1つの答えとして「成長分野に少しでも参加したい」だった。挙げたファンドシリーズはどれも未来を作る成長分野に集中的に投資するアセットを持っている。「投資が趣味」「未来に興味がある」、「リスクを取れる」のような価値観があればインデックス投資以外の選択肢としては面白いと思う。
Nand2Tetris 11章までの感想
「Nand2Tetris」について、最後に記事を書いてから4ヵ月も経過してしまった。
決して怠けていたわけではなく、この間に「Nand2Tetris」の11章の「コンパイラ作成」までクリアした。
おさらいになるが、Nand2Tetrisは「ハードウェア」と「ソフトウェア」2つのパートから構成されている。 ハードウェアまでは1章ごとに、感想を書きながら進められたのだが、ソフトウェアパートからの演習は非常に手応えがあり(ありすぎて)、感想を書く余裕がなかった。
というわけで、今回は「Nand2Tetris」の感想をまとめて記事にした。
5章 : コンピュータアーキテクチャ
ハードウェアの総仕上げ:CPU構築
このパートでは1章~3章で作成した論理ユニットを組み合わせて、Hackコンピュータと呼ばれるNand2Tetris専用のコンピュータを作成する。
この章の山場はなんといっても「CPU構築」だ。
HackCPUはとても単純なアーキテクチャなので、レジスタも2つしか用意されていない。そのうちの1つのはAレジスタと呼ばれ、メモリアドレスを指定するモード、値として仕様するモードがあるため、概念理解に苦戦した。
ちなみに本書には答えは載ってないものの、大まかな素案が提示されているので、それを参考にしてCPUを作成した。

そしてCPUの肝は、デコーダー(decode)だ。デコーダーはCPUの命令セットを解釈するためのユニットで、CPUの命令セットデコードには、機械語の理解が必要不可欠だ。本書ではデコーダーの部分だけは自分で考えて、実装することになっている。5章までは丁度いい難易度だと感じた。(6章から大変なことを意味する)
作成したCPUは下記。 https://github.com/i-net-singularity/nand2tetris_projects/blob/main/05/CPU.hdl
CPUの単体テストをクリアすることを優先したため、ロジックの最適化は2周目の楽しみに取っておく。(言い訳) あとは、「メモリ」を組み上げ、先に述べたCPUとつなぎ合わせ「Hackコンピュータ」を作るところまでが5章の内容だ。
6章 : アセンブラ
6章からソフトウェアパートになる。 正直「CPU」作成したら、残りのソフトウェアパートは楽勝だろうと思っていたが、大間違いだった。
ソフトウェアパートでは最初に、HackCPU用のアセンブラを作成する。 "好きなプログラム言語を使ってアセンブラを作成せよ" というのが本書の方針なので、勉強も兼ねてPythonを選んだ。この辺は本当に好みだが、Pythonで作っている方が多いかな。
※結果的にPythonを選択したのは正解だった。 Pythonが持っている組み込み関数の力が大いに発揮された。
ちなみにアセンブラとは、アセンブリ言語で記載された原始的なソースコードを機械語に変換するプログラムのことだ。 アセンブリはソースコードの1行=機械語の1行に対応している。アセンブラの動きは入力されたソースコードを1行ずつ機械語に変換していくという単純なものになる。Python学習も兼ねるには丁度良い難易度だ。
この章で学ぶ最初の重要な概念は「シンボルテーブル」かと。 …と言っても難しいものではなく、入力されたソースコードに登場するシンボル(変数)を管理するテーブルだ。 「シンボルテーブル」の登録/参照がアセンブラの肝だった。アセンブラ開発は考える部分も少なく、1週間ぐらいで作成できた。
成果物
作成したアセンブラは下記。 https://github.com/i-net-singularity/nand2tetris_projects/blob/main/06/n2t_hack_assenbler_byPy/n2t_hack_assembler.py
7章~8章 : バーチャルマシン言語
7章~8章の目的は、バーチャルマシンと呼ばれるスタックベースの仮想コンピュータの言語を学び、バーチャルマシン言語(以下VM言語)をアセンブリに変換するVMトランスレータを作成することだ。
この章から、1章ごとの演習ボリュームが多くなり苦戦した。
7章8章の肝はスタックマシン。 スタックマシンの働きはとても単純なのに複雑な演算ができてしまうのは本当に良く考えられている。 バーチャルマシンで、以下概念をしっかり理解すれば先に進めるはずだ。
- バーチャルマシンのメリット
- スタックマシン
- メモリセグメント
7章 : 前半パート
下記機能を記した中間コードをアセンブリ言語に変換するプログラムを作成する。
- 算術演算
- メモリアクセス
算術演算でスタックマシンの働きを学び、メモリアクセスではHackコンピュータのメモリセグメントの働きを学ぶ。 メモリセグメントは後々の高水準言語で変数のスコープを実現するために必要な概念となる。 この章の時点だと、自分はメモリセグメントの重要性に気づけなかった。
8章 : 後半パート
7章で作成したプログラムを拡張し下記機能を追加する。 8章の演習を全てクリアした暁には、VM言語をアセンブリに変換できる完全なVMトランスレータが完成しているはずだ。
- プログラムフロー
- サブルーチン呼び出し
サブルーチン呼び出しの仕組みは非常に面白く感じた。 スタックマシンのシンプルでエレガントな働きによってサブルーチンが見事なまでに実現されていた。
成果物
作成したVMトランスレータは下記。 https://github.com/i-net-singularity/nand2tetris_projects/blob/main/08/n2t_hack_vm_translator.py
9章 : Jack言語
9章では、Jack言語という高水準言語を学ぶ。 Jack言語は、JavaやC#に似た文法を持つ、本書専用の学習用オブジェクト指向言語だ。 コンパイラ作成がしやすいようにかなり上手く設計された言語で、本章でJack言語の文法習得を通して、コンパイラ作成の基礎を固めることになる。
この章は、他の章と違ってJack言語の文法を学ぶためだけの章なので少し毛色が違う。自分は1回読んだだけで、次に進んだ。
しかしながら、次章のコンパイラ作成の段階になってから、9章は何度も読み返した。 基本的に大切な仕様がさらっと書かれていることが多く、見落とすことが多々あった。
10章~11章 : Jackコンパイラ
いよいよコンパイラだ。 コンパイラは10章~11章の2章に分けて開発する。

Jackコンパイラは、Jack言語のソースコードを読み込みVM言語を出力する働きをもつ。実際のコンパイラと違って出力結果はテキストファイル形式のVMファイルなので、出力結果の確認は容易な部類になる。
自分はコンパイラ理論など全くの無学だったため、コンパイラ作成が一番苦労した。 人によっては1週間で出来る人もいるらしいが、私は2ヵ月弱ぐらい要した。 とはいえ、ステップを踏みながら、1歩1歩進めば、必ずコンパイラを作成できるようになっているから安心してほしい。
ファーストステップ
コンパイラ作成にあたり、いくつか重要な概念を学ぶ。 解説したいところだが余白がたりないため、説明は他者様に委ねる。
10章 : 前半パート
10章では、まずソースコードをトークナイザーでトークンと呼ばれる最小構成要素に分解する。 次にパーサーでJack言語の文法に従ってツリー構造のXMLファイルを生成する。
- トークナイザー
- パーサー
この章の演習をクリアしないと11章に進めないので、この章は非常に重要だ。
11章 : 後半パート
10章をクリアできれば、あとはパース内容をコードに変換する「コードライター」を作成するだけだ…。 自分の場合「コードライター」が本書の中で一番苦戦した。 ちなみに多くの人は、前章の「パーサー」で苦戦や挫折するようだ。
開発の流れ的には本書の構成どおり、下記を順番に作るのが良いだろう。
- シンボルテーブル作成
- データ変換
- コードライター
コードライターでは、パース結果に応じたVM言語を出力する。 ここで、「コンストラクタ」や「インスタンス」といったオブジェクト指向言語の重要な概念をVMレベルでどのよう実現するかを通して、オブジェクト指向の真の意味を学べた気がした。(あくまで個人の感想です)
その他、シンボルテーブルだが、似たような概念を既に学習済みだ。そう、アセンブラだ。 アセンブラでは機械語生成のためにソースを2度読みする必要があったが、コンパイラは最初の1回の読み込みで解析が完了するところだろうか。
データ変換はシンボルテーブルに基づいて、Jack言語内の変数をインデックスに変換する処理だ。この辺りは、特に苦戦する箇所はなかった。実際のコンパイラでは、実用的なシンボルテーブルはハッシュテーブルがチェインした構造になるようだ、Jackは単純な仕様のため2つのシンボルテーブルだけで済む。
コンパイラ作成方針
コンパイラは無学者が取り組むには非常に手ごわい。 そこで、以下方針でコンパイラを作成した。
公式サイトに用意している講義形式PDFをちゃんと読む
公式サイトの講義形式PDFは、本書の内容の詳細について説明がある。 本書の内容を一通り読んだあとに講義資料を読むと、より深く理解できる。 何よりも、講義資料にはコンパイラ作成のヒントが満遍なく書かれているので必読だ。
-
本書ではXML出力からVM出力に切り替えていたが、私はXML出力を止めずに追加でVM出力をするようにした。 理由は簡単で、XMLの構文解析結果が「コードライター」のデバッグに役立ったからだ。
公式サイトのJackコンパイラの出力結果を解析した
自作コンパイルだけだとデバッグはとても難しいものとなる。 そこでちょっとズルいけど、お手本のコンパイル結果と比較解析する手法を採った。 しかし、おかげで自身のコンパイラの間違っている箇所を効率的に見つけることができた。
成果物
P 作成したコンパイラは下記。 https://github.com/i-net-singularity/nand2tetris_projects/blob/main/11/n2t_jack_analyzer.py
コンパイラに関しては、他の方々が作成したコンパイラを大いに参考にした。
総括と今後の課題
本書の醍醐味は、ハードウェアからソフトウェアまでの知識が一直線に繋がったときの達成感かと思う。 コンピュータサイエンスに興味がある方は、取り組む価値があるはずだ。
突っ込みどころは、Nand2Tetris と謳いながら、Tetris が登場しないでPong と呼ばれるピンポンゲームで終わったことだろうか。
実はまだ12章(オペレーティングシステム作成)は未着手だ。 「コンパイラまでやりきる」と決めて取り組んだので、いったん一区切りつけることにした。
11章まで終わった段階だと自作コンパイラができていて、OSはビルトインのVMライブラリを使っている状態だ。 この状態では、「コンパイラを自作してプログラムを動かせた」とは言えないので、時間と心の準備が整い次第、12章に取り組む所存だ。
その他の課題としては、「各章の成果物の最適化」、「テトリス開発」、「FPGAへの実装」などを考えたい。 やるべきことが沢山ありすぎて、どれから手をつけていいか…こういう状態を楽しみたい。
進展があり次第、また報告するのでよろしくです!
Nand2tetris 4章の感想
「Nand2tetris」について、4章の感想を書く。ちなみに執筆次点で6章まで完了している。 当初の目標通り、5章までは4月中に完遂できた。
下記図の赤枠で囲った該当箇所だ。(5章は次回に書く)

4章 : 機械語
4章では、HackCPUの機械語仕様を学ぶ。 機械語はコンピュータアーキテクチャの上位にあたる概念だが、理解を深めるため本書では先に学ぶようだ。
先に機械語の仕様を学ぶことで、5章で作成するCPUがどのようにプログラムを処理するのかイメージしやすくなった。
Hack機械語はA命令、C命令の2種類からなる。 A命令は、Aレジスタに値をセットする命令で、C命令はALUによる演算指示コマンドだ。 今回は概略と感想がメインなので詳しくは延べないが、Hack機械語の仕様は下記サイトで確認できる。 https://www.nand2tetris.org/project04
本章のお題目としてHack仕様に基づいたアセンブリ言語でプログラムを作成することになる。
日頃、高水準言語(C言語)しか使ったことが無かったので、FOR文やIF文のありがたみを痛感した。これからはもっとC言語を敬いたい。(合掌)

Hackアセンブリ言語の鍵は、AコマンドとAレジスタを使いこなすことだろう。 ちなみに唐突に"Hack"という言葉が出てきたが、Hack とは本書で作成するコンピュータのアーキテクチャ名のことだ。
Hack仕様のAコマンドは、"@xxxx" の形式から成るコマンドで、用途はシンボル(変数)を表現、Aレジスタに値をセット、メモリアドレスの表現とHackアセンブリの肝となるコマンドだ。
演習
2つのプログラムをHackアセンブリ言語で作成することになった。
乗算プログラム 指示されたメモリに格納された2つの数値を掛け算し、結果を指定されたメモリに格納するプログラム。HackCPUではCPU命令セットとして乗算が用意されていないので、プログラムで実装する必要がある。乗算はこのあと実装する高水準な言語の前哨戦といったところだろうか。 慣れないAコマンドの使い方はこの演習で学べる。 作成したプログラムは下記を参照してほしい。 https://github.com/i-net-singularity/nand2tetris_projects/blob/main/04/mult/Mult.asm
入出力確認プログラム Hackにはキーボードとディスプレイという2つの仮想的なデバイスが接続されている。 キーボードから入力した文字をディスプレイに表示するプログラムを作成した。 この演習で「メモリマップ」という概念を学んだ。メモリアドレス空間の一部をデバイスに割り当てることで、デバイスとのやり取りを実現する仕組みだ。「メモリマップ」の概念を学んだことで、コンピュータに接続できるデバイス種類が自由自在に設計できる点と、デバイスドライバの仕組みが少し理解できた。 https://github.com/i-net-singularity/nand2tetris_projects/blob/main/04/fill/Fill.asm